[최신 업데이트 소스 위치]
내용을 계속 수정 보완 중이라서, 최신 내용은 아래 링크를 참고해 주세요.
- 영상 자막 추출 후 DeepL 앱/웹으로 워드파일을 이용하여 수동 번역을 원할 경우: https://github.com/sevengivings/subtitle-extractor
- 영상 자막 추출 후 구글/파파고/DeepL/DeepL-Rapidapi 번역 API(유료, 일부 용량 무료 제공)를 이용하고 싶을 경우: https://github.com/sevengivings/subtitle-xtranslator
(주의) 아래 글을 처음 쓸 때와는 좀 많이 다른 결말(?)로 가면서 글이 좀 짬뽕이 되었습니다. 좀 정리하기는 했으나 바쁘신 분은 그냥 위 github의 설명을 참고하시는 것이 나을 것 같아요. 제 프로그램은 따로 WebUI가 없기 때문에 처음에는 낯설 수 있습니다.
subtitle-xtranslator.py에 아주 기초적인 WebUI를 추가해서, Colab에서도 작동 가능합니다.
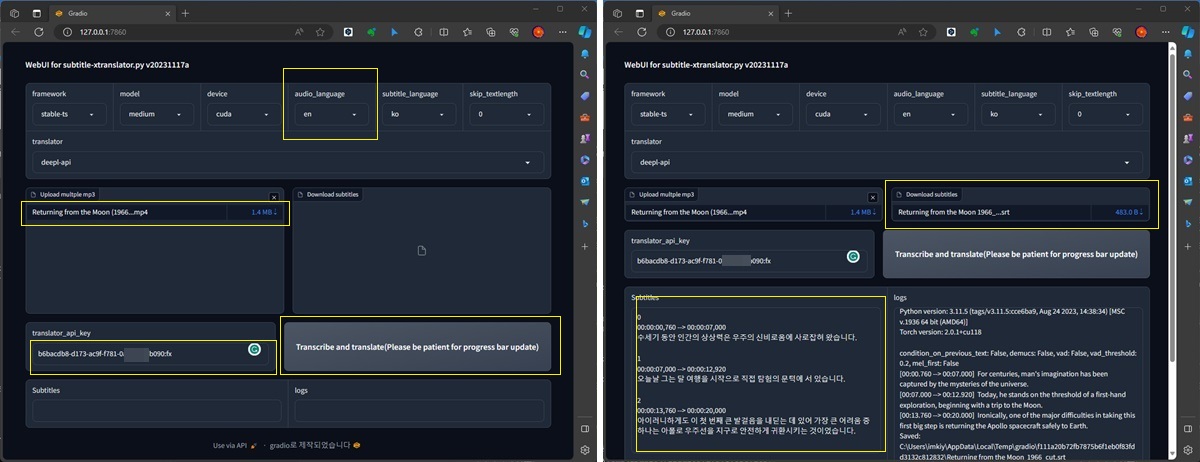
일단 subtitle-xtranslator.py나 subtitle-extractor가 작동하는 환경에서 pip install gradio를 하고 나서 python app.py로 실행하시면 됩니다. 실행 경로(PATH 환경 변수)에 ffprobe.exe(리눅스는 sudo apt-get install ffmpeg)가 있다면 비디오 길이와 추출된 자막의 시각을 비교하여 진행률을 계산하고, 약 6천 바이트 가량 로그가 쌓이면 progress 진행 바가 갱신이 됩니다. 한번에 여러 파일 처리도 가능합니다. Colab의 경우에는 한번만 정상 작동하는 문제가 있습니다. 그럴 때에는 Colab 가상 머신의 메뉴에서 "런타임 다시 시작"을 선택하고 !python app.py를 다시 실행해 주세요. Colab에서는 ffmpeg을 별도로 설치하지 않아도 되었습니다.
아래에는 명령어 라인을 이용하여 작업하는 동영상도 첨부했는데 subtitle-extractor.py(수동 DeepL 앱 번역)와 subtitle-xtranslator.py(자동 API 번역)를 실제로 돌려보는 동영상들입니다. 설치만 잘하면 사용은 크게 어렵지 않습니다.
2023.08.16.부터 DeepL이 우리나라도 공식 지원을 하고 있습니다. DeepL API Free 개발자 등록을 하면 월 50만자까지 무료로 이용이 가능합니다. DeepL Python Library도 제공하고 있으므로 어렵지 않게 구현이 가능하게 되었습니다. 이제 subtitle-extractor.py에서는 DeepL API 파일 번역을 이용한 자동 번역을 지원합니다. => 파일번역 방식은 횟수 제한이 있어서 사용하지 않는 것이 좋겠습니다. 대신 글자 단위 DeepL API 번역을 지원하는 subtitle-xtranslator.py 를 이용해 주시기 바랍니다.
[인공지능 음성인식 자막 생성에 대하여]
OpenAI의 Whisper로 비디오 파일에 있는 음성을 문자(텍스트)로 추출할 수 있습니다. 사용하는 GPU성능에 따라 다르기도 하고 비록 완벽하지는 않지만 대략 의미가 통하는 정도로 활용이 가능합니다.
- 오리지널 Whisper : https://github.com/openai/whisper
- Whisper에 WebUI를 추가한 사람 : https://github.com/openai/whisper/discussions/397
- Whisper를 조금 더 개선한 stable-ts : https://github.com/jianfch/stable-ts
- Whisper를 좀 더 빠르게 적은 메모리를 사용하게 하는 whisper-ctranslate2 혹은 faster-whisper : https://github.com/guillaumekln/faster-whisper
stable-ts는 위의 오리지널 Whisper를 조금 더 수정해서 자막 제작에 좀 더 특화되었다고 하는데 깃헙에 써 있는 메모를 번역해 보면,
- regroup=True를 통해 세그먼트 나눌 때 좀 더 자연스러운 경계로 하고,
- suppress_silence=True를 통해 시각정보 정확도를 올리고 침묵 구간 처리를 더 잘하고,
- demucs=True는 원래 음악용인데 음악이 없을 때에도 잘 작동한다고 합니다
- 세그먼트 시각정보 신뢰성을 높이려면 word_timestamp는 false로 하지 말라고 합니다. -> 자막 파일이 너무 커지므로 false로 해야합니다.
- Whisper보다 못하다고 느껴지면 mel_first=True 등등라고 합니다.
그외에 demucs와 vad에 대해 잠시 더 언급하자면,
- demucs 옵션을 사용하기 위해서는 pip install demucs PySoundFile, vad를 위해서는 pip install silero 가 필요합니다.
- demucs 옵션을 켠 경우 긴 파일을 처리하기 위해서는 8GB VRAM이 부족한 것 같습니다.
- vad와 demucs 모두 처리하는 데 몇 분 가량 추가 소요가 되는데 일단은 메모리와 시간 문제로 접어두어야 할 듯합니다.
아래 코드는 subtitle-extractor.py나 subtitle-xtranslator.py에 stable-ts의 처리 부분에서 위 내용을 추가해 본 모습입니다. subtitle-extractor.py는 아래와 같이 수정하여 이용할 수 있으며, subtitle-xtranslator.py에서는 추가 커맨드 라인 옵션으로 구현해 놓았습니다.
result = model.transcribe(verbose=True, word_timestamps=False, condition_on_previous_text=True, \
demucs=True, vad=True, mel_first=True, \
language=audio_language, audio=input_file_name)
테스트를 정교하게 한 것은 아니지만, stable-ts(버전 2.6.x~2.7.x 기준)가 오리지널 Whisper(2023년3월)나 Whisper WebUI(2023년1월)보다 더 나은 자막이 나오는 것 같았습니다. 저는 잘 이용하지 않지만 Whisper WebUI는 계속 기능 추가 및 갱신되었으니 한번 사용해 보시는 것도 좋을 것 같아요.
stable-ts에 대한 제 의견과 달리 모두 계속 버전업이 되므로 최신 버전으로 테스트하다가 불만족 시 버전을 바꾸는 것이 좋겠습니다(참고: 아래는 stable-ts의 버전을 낮추는 예시인데, openai-whisper도 구버전 20230314로 낮아집니다. 만약 버전이 꼬이면 venv를 삭제하고 다시 만들어야 합니다).
pip install stable-ts==2.6.2
아래는 Whisper의 대표적인 문제들입니다(참고로, 아래 댓글을 보시면 condition_on_previous_text=False 를 추가하면 해결된다고 합니다: 되지만 완전히는 아닐 거라고... 어쨌든 stable-ts나 whisper명령어로 음성자막추출 시 명령어 옵션에 --condition_on_previous_text=False를 추가해서 사용하는 것이 낫다는 의견입니다. 하지만 stable-ts 깃헙에서는 True로 쓰라고 추천하므로 경험적으로 끄거나 켜야할 것 같아요.)
- 아무 말도 안하는데 귀신 자막이 만들어지는 문제(일부 영상의 경우 아무런 음성이 없는데도 대표적인 인사말 등이 나타납니다)
- 도중에 처리가 중단되면서 마지막 자막이 무한 반복되는 문제
사실 제가 파이썬 스크립트를 만들기 시작했던 이유가 자막을 분석해서 내용 이해에 불필요한 한 두 글자의 짧은 자막을 제거하고 싶다는 생각에서 비롯되었습니다. DeepL 번역 기능을 쓰다보니까 시각 정보에 이상이 생겨서 해결하고자 자막 텍스트만 추출하였고, 3천(5천)자 클립보드 번역이 불편하므로 docx로 저장하여 DeepL의 파일 번역 기능을 쉽게 사용하게 했습니다. 이후 자막 추출 기능(Whisper, stable-ts)도 포함하고, API 번역 기능까지 추가(subtitle-xtranslator.py)하게 된 것입니다..
[파이썬 설치 후 자막 추출 과정]
아래에서는 stable-ts를 NVIDIA 그래픽 카드가 달린 윈도우11에서 파이썬을 설치해서 자막을 추출하는 과정을 적어 보았습니다(어려운 점은 없지만).
참고로 Whisper의 Medium모델 이상을 써야 자막 품질이 좋으므로 8GB이상의 VRAM을 가진 NVIDIA 게이밍 그래픽카드가 필요합니다. 노트북과 같이 VRAM이 작은(예: 2GB)의 경우는 이 글도 참고하세요. 테스트는 안 해 봤지만 6GB VRAM카드도 될 듯합니다. CPU만으로도 가능하긴 하지만 처리 속도가 많이 느립니다.
파이썬 설치
파이썬이 현재 3.11.4이 릴리즈 중이고 적당히 높은 버전(3.8.x이상)을 설치하면 됩니다. 윈도우11의 명령 프롬프트나 파워쉘 아무데서나 python이라고 치면 실행될 수 있도록 하는 것이 목표입니다.
CUDA 설치
Whisper WebUI에서는 cuda 11.7을 requirements.txt에 명시를 해 놓았지만, cuda 11.8이나 12.2를 설치해도 됩니다. 최신 버전을 설치하는 것이 좋겠네요.
추가로 cuda버전에 맞는 cuDNN도 받아서(NVIDIA 개발자 계정이 필요) 압축 해제 후 include와 lib 디렉터리의 내용을 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.2에 덮어쓰기하면 좋은데, cuDNN은 없어도 작동할 것 같습니다. 단, 적은 VRAM에서도 8bit 양자화를 이용하여 작동 가능하고 빠른 처리가 가능한 faster-whisper를 이용하려면 cuDNN과 cuBLAS(pip install nvidia-cublas-cu12)도 필요합니다.
cuda가 설치되어 있는 지 확인하려면 파워쉘(Windows PowerShell 앱)을 띄우고, nvidia-smi 라고 명령을 내려 보면 알 수 있습니다. 요즘은 왠지 그래픽 드라이버만 설치되어도 아래 명령이 실행되는 것 같습니다.
어쨌든 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA 폴더가 있다면 설치가 된 것이겠습니다.

파워쉘 실행
윈도우키를 누르고 R키를 누르면 좌측에 실행 창이 나타납니다. 이곳에 "powershell"을 입력하고 확인을 누르면 파워쉘을 실행할 수 있습니다(이외에 다양한 방법으로 실행 가능).
파워쉘 창에서 python이라고 치고 [Enter]키를 누르면 다음과 같이 응답이 나와야 합니다.
PS C:\Users\사용자명> python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
위 >>> 에서 나오기 위해서는 exit() 을 입력합니다.
VENV 환경 만들어 주기 및 파이썬 패키지 설치하기
파이썬은 패키지를 필요할 때마다 설치하게 되는데, 시스템에 설치된 파이썬에 그냥 설치하다보면 가끔 뭔가가 꼬이게 되고 문제가 가끔 생기는데 아주 머리가 아픈 경우가 있습니다. 물론, 이 기능만 이용하겠다하면 상관없지만 그래도 제거가 편하도록 가상의 환경을 만들어 줍니다. 아래는 사용자 디렉터리에 그냥 설치했는데 다른 드라이브나 폴더에 해도 됩니다(주의: 경로 상에 한글이 없는 곳에서 작업해주세요. 혹시 윈도우 로그인명이 한글이라면 다른 곳에 설치가 필요합니다.)
PS C:\Users\사용자명 > python -m venv venv
PS C:\Users\사용자명 > .\venv\Scripts\Activate.ps1
혹시 .\venv\Scripts\Activate.ps1 가 실행이 안되면, 관리자 권한으로 파워쉘을 실행하고, Set-ExecutionPolicy -ExecutionPolicy RemoteSigned 를 해주면 실행이 됩니다.
위와 같이 해주면, 가상 환경 준비가 끝납니다. 처음에 실행할 때 보안 관련 문의가 나오는데 Always를 선택해 줍니다. venv가 성공적으로 실행되면 프롬프트가 바뀝니다. 이 상태에서 필요한 패키지들을 설치합니다.
먼저 GPU버전의 토치를 설치합니다.
(venv) PS C:\Users\사용자명 > pip install torch==2.0.1+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
(venv) PS C:\Users\사용자명 > pip install torch --index-url https://download.pytorch.org/whl/cu121
stable-ts는 최신 버전을 설치해 줍니다.
(venv) PS C:\Users\사용자명 > pip install -U stable-ts
잘 설치가 되었는 지 확인하기 위해 python을 입력하고 간단한 프로그램을 짭니다. __version__ 은 언더바가 2개씩 좌우로 있습니다.
(venv) PS C:\Users\사용자명> python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> print(torch.__version__)
2.2.1+cu121
>>> exit()
잘 설치가 되었네요.
만약 아래와 같이 안된다면 추가로 설치를 해 줄 것이 있습니다. https://aka.ms/vs/16/release/vc_redist.x64.exe
(venv) PS C:\home\python> python
Python 3.11.5 (tags/v3.11.5:cce6ba9, Aug 24 2023, 14:38:34) [MSC v.1936 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
Microsoft Visual C++ Redistributable is not installed, this may lead to the DLL load failure.
It can be downloaded at https://aka.ms/vs/16/release/vc_redist.x64.exe
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\venv\Lib\site-packages\torch\__init__.py", line 133, in <module>
raise err
OSError: [WinError 126] 지정된 모듈을 찾을 수 없습니다. Error loading "C:\venv\Lib\site-packages\torch\lib\c10.dll" or one of its dependencies.
이 글에서는 stable-ts만 설치했는데, subtitle-extractor 혹은 subtitle-xtranslator의 설치 설명서에 whisper 및 faster-whisper 등의 설치 방법이 추가로 나와 있습니다.
pip install git+https://github.com/openai/whisper.git
pip install faster-whisperFFMPEG 설치 및 파이썬 프롬프트에서 영상 자막 만들어 보기
영상에서 음성을 추출을 하다보니 외부 프로그램이 하나 필요합니다.
- https://www.gyan.dev/ffmpeg/builds/#release-builds 에서 ffmpeg-release-essentials.zip 을 받아서 압축 해제한 후,
앞으로 작업할 디렉터리나 환경변수에서 Path가 설정되어 있는 곳에 복사하여도 됩니다. 아니죠...그냥 C:\Users\사용자명\venv\Scripts 밑에 복사하는 것이 속편하겠습니다.
짧은 영상 하나를 테스트하는 과정을 보여드립니다(실제로는 중간에 warning이 나오지만 작동에 문제는 없습니다).
(venv) PS C:\Users\사용자명> python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> import stable_whisper
>>> model = stable_whisper.load_model("small", device="cuda")
>>> result = model.transcribe(verbose=True, word_timestamps=False, language="ko", audio="20220902_131203.mp4")
[00:12.800 --> 00:16.080] 아 아까 딱 찍었어야 되는데
[00:19.580 --> 00:21.580] 불행랑을 치는 걸 찍었어야 되는데
[00:30.000 --> 00:34.980] 진출하되겠지
>>> result.to_srt_vtt("20220902_131203.srt")
Saved: C:\Users\사용자명\20220902_131203.srt
>>> exit()
word_timestamps=True가 기본 값인데, 말하는 중 단어가 하이라이트 되는 기능이 있습니다. 2GB의 VRAM을 가진 그래픽카드라서 small 모델로 했는데, 몇 마디(불행랑->줄행랑, 진출하되겠지는 그냥 파도 소리가 자막화 되었네요)는 잘못 인식했네요. 8GB VRAM이라면 medium으로 하면 됩니다. 만들어진 SRT의 내용은 다음과 같습니다.
0
00:00:12,800 --> 00:00:16,080
아 아까 딱 찍었어야 되는데
1
00:00:19,580 --> 00:00:21,580
불행랑을 치는 걸 찍었어야 되는데
2
00:00:30,000 --> 00:00:34,980
진출하되겠지
Whisper는 추출된 자막을 영어로 번역하는 기능만 들어 있어 있어서 따로 설명은 생략합니다.
일단 모든 게 잘 돌아가니까, 이제는 command line으로 처리해 봅니다. 이번에는 word_timestamps 옵션과 verbose 도 뺍니다(자세한 인자들은 stable-ts [Enter]를 해보시면 나열 됩니다).
(venv) PS C:\Users\사용자명 > stable-ts --model small --device cuda --output_format srt --language ko .\20220902_131203.mp4
.\20220902_131203.srt already exist, overwrite (y/n)? y
Loaded Whisper small model
100%|███████████████████████████████████████████████████████████████████████████| 36.01/36.01 [00:37<00:00, 1.04s/sec]
Saved: C:\Users\사용자명\20220902_131203.srt
이제 자막이 단어별로 넘어가기 때문에 좀 길게 나왔습니다. "진출하되겠지"는 "iết은 괜찮은 건가?"와 "그게"로 또 잘못 인식되었네요.~
0
00:00:00,520 --> 00:00:13,100
<font color="#00ff00">아</font> 아까 딱 찍었어야 되는데
1
00:00:13,100 --> 00:00:13,420
아 <font color="#00ff00">아까</font> 딱 찍었어야 되는데
2
00:00:13,420 --> 00:00:14,460
아 아까 <font color="#00ff00">딱</font> 찍었어야 되는데
3
00:00:14,460 --> 00:00:15,020
아 아까 딱 <font color="#00ff00">찍었어야</font> 되는데
4
00:00:15,020 --> 00:00:15,380
아 아까 딱 찍었어야 <font color="#00ff00">되는데</font>
5
00:00:15,380 --> 00:00:20,120
<font color="#00ff00">불행랑을</font> 치는 걸 찍었어야 되는데
6
00:00:20,120 --> 00:00:20,320
불행랑을 <font color="#00ff00">치는</font> 걸 찍었어야 되는데
7
00:00:20,320 --> 00:00:20,380
불행랑을 치는 <font color="#00ff00">걸</font> 찍었어야 되는데
8
00:00:20,380 --> 00:00:20,740
불행랑을 치는 걸 <font color="#00ff00">찍었어야</font> 되는데
9
00:00:20,740 --> 00:00:21,020
불행랑을 치는 걸 찍었어야 <font color="#00ff00">되는데</font>
10
00:00:30,000 --> 00:00:34,880
<font color="#00ff00">요</font> biết은 괜찮은 건가?
11
00:00:34,880 --> 00:00:35,900
요 <font color="#00ff00">biết은 괜찮은 건가?</font>
12
00:00:35,900 --> 00:00:36,000
<font color="#00ff00">그게</font>
이제 파이썬으로 stable-ts를 이용한 자막 추출이 가능해졌으므로 3가지 유틸리티를 소개하려고 합니다.
- pysub-parser를 이용하여 .srt에서 자막만 추출한 후, DeepL 앱의 파일(.docx) 번역 기능을 이용하는 유틸리티
- subtitle-extractor.py는 stable-ts/whisper를 이용하여 자막도 추출하고, DeepL 앱의 파일 번역 이용을 도와주는 유틸리티 + 불필요한 자막 제거 기능
- subtitle-xtranslator.py는 stable-ts/whisper를 이용하여 자막을 추출한 후, 각종 번역 API를 지원하는 유틸리티 + 불필요한 자막 제거 기능
[DeepL 앱 이용 파일 번역을 도와주는 간단한 유틸리티]
아래 방법의 장점을 요약합니다.
- 무료 DeepL 번역의 클립보드 방식 복사 붙여 넣기의
5천3천 글자 제한에서 자유롭습니다. => 파일 번역을 이용합니다. - 파일 번역에 필요한 .docx를 만들기 위해 MS 워드가 없어도 됩니다. 워드패드로도 될 수도 있지만... 영 불편한 프로그램이죠. => 파이썬 코드로 자막을 워드 파일을 만들어서 DeepL 파일 번역에 이용합니다.
- DeepL에서 번역과정에서 자막 시각 정보에 발생시키는(?) 오류(예: 03:02:00:13 등으로 시분초 외 정보가 추가됨)를 방지할 수 있습니다. => 시각정보 제외 자막 문자들만 번역해야겠습니다.
- (반 농담입니다만)텍스트만 번역을 시키므로, 용량이 줄어들어서 DeepL에 조금 덜 폐를 끼칩니다(?) => 환경 보호(?)
아직 우리나라에는 DeepL API가 지원이 안되고 있지만 파일 번역 기능은 로그인 없이도 (웹사이트, 윈도우 DeepL App 등)사용이 가능합니다.
파일 번역은 클립보드(복사 붙여넣기)로 붙여 넣어서 번역하는 것과 달리 한번에 5천 3천 글자 제한이 없어서 편리하지만, 다음 2가지 문제가 있습니다.
- 자막 파일의 경우 번역 후에 시간 정보 쪽에 드문드문(몇 십 군데) 시:분:초 자료에 글자가 추가되는 오류가 나기도 하고,
- 무료 버전은 파일 번역을 하더라도 하루 최대 이용 글자 수도 10만 글자로 제약이 있으므로, 굳이 시간 정보를 번역 시킬 필요도 없습니다.
그래서 자막 텍스트만 "입력파일명.docx"로 저장한 후 DeepL에서 번역된 "입력파일명 ko.docx"를 다시 시간 정보와 합쳐주는 파이썬 유틸리트 프로그램을 만들어 보았습니다(구글 Bard 및 AWS CodeWhisperer 이용).
사용법은 python3 .\srt_deepl_util.py .\입력파일명.srt (.\는 파워쉘일 경우에 추가)이며, 프로그램이 중간에 멈춘 사이에 (한국어로 번역하면) "입력파일명 ko.docx"이 만들어지도록 DeepL App에서 파일 번역을 해주신 후 [Enter]를 누르면 번역이 완료된 새로운 자막파일이 완성됩니다.
- 편의상 자막(.srt)과 파이썬 프로그램은 같은 디렉터리(폴더)에 있는 것이 좋습니다.
- 참고로 DeepL for Windows App을 사용하여 파일 번역하면 같은 폴더에 저장해 줍니다.
- 팁: 입력파일명.srt를 입력할 때, *.srt라고 먼저 타이핑한 후 [tab]키를 누르면 파일명을 (한번 혹은 여러 번 눌러서) 자동 완성해 주어서 편합니다.
사용하기 전에 다음 명령을 한번 해줍니다. 위에서 만들었던 venv환경에서 그대로 작업합니다.
- pip install python-docx (https://pypi.org/project/python-docx/)
- pip install pysub-parser (https://pypi.org/project/pysub-parser/)
srt_deepl_util.py
import sys
import docx
from pysubparser import parser
# Extract text from .srt files and save them as .docx files.
# For translation, use the DeepL app or the free version of the DeepL website.
# Recreate translated .srt files using the .docx output from DeepL.
def translate_subtitles(input_file_name):
if not input_file_name.endswith(".srt"):
print (".srt로 끝나는 자막 파일을 입력으로 사용합니다.")
return
subtitles = parser.parse(input_file_name)
output_file_name = input_file_name.rsplit(".", 1)[0] + ".docx"
# save subtitle texts and times for later usage
subtitle_texts = []
start_times = []
end_times = []
doc = docx.Document()
for subtitle in subtitles:
para = doc.add_paragraph()
run = para.add_run(subtitle.text)
# save subtitle texts and times for later usage
subtitle_texts.append(subtitle.text)
start_times.append(subtitle.start)
end_times.append(subtitle.end)
doc.save(output_file_name)
print ("자막 글자만 다음 파일에 저장됨: " + output_file_name)
#===============================================================
# wait for translated docx
print (">> 주의: 파일 번역은 DeepL App이나 웹사이트에서 직접 해주셔야 합니다(로그인 불필요).")
input(">> " + output_file_name + "을 DeepL에서 한국어로 파일 번역한 후 [Enter]를 누르세요...")
#===============================================================
# read translated docx
# " ko" is appended to the file name by DeepL
translated_docx = output_file_name.rsplit(".", 1)[0] + " ko.docx"
docx_file = docx.Document(translated_docx)
# Remove empty line
translated_texts = []
for paragraph in docx_file.paragraphs:
if len(paragraph.text) < 1:
continue
translated_texts.append(paragraph.text)
# check length of translated texts and original texts
if len(subtitle_texts) != len(translated_texts):
print ("오류 자막의 갯수가 맞지 않습니다. SRT의 자막수 vs. 번역된 자막수")
print (len(subtitle_texts), len(translated_texts))
return
translated_subtitle = output_file_name.rsplit(".", 1)[0] + " ko.srt"
with open(translated_subtitle, "w", encoding="utf-8") as f:
i = 0
for start, end, text in zip(start_times, end_times, translated_texts):
f.write (f'{i}\n{start} --> {end}\n{text}\n\n')
i += 1
print ("번역된 자막 생성 완료: " + translated_subtitle)
if __name__ == "__main__":
# pass file name as argument
if len(sys.argv) > 1:
input_file_name = sys.argv[1]
translate_subtitles(input_file_name)
sys.exit(0)
else:
print ("사용법: python3 srt_deepl_util.py <input_file_name>")
sys.exit(1)* 참고 및 주의 사항
- 한 시각에 여러 줄로 된 자막은 pysub-parser가 처리를 못하는 듯합니다. 한 줄로 만든 후 작업해 주세요.~
- 위의 소스 코드를 복사해서 .py 파일을 만들 때에는 윈도우11(10)의 노트패드에서 저장해 주시고, 인코딩이 UTF-8로 되어야 합니다. 노트패드 오른쪽 아래 구석에 보면 보통 UTF-8이 기본으로 되어 있어요. 물론 Notepad++나 VSCode같은 코딩을 염두에 둔 에디터들을 쓰셔도 됩니다.
[자막 추출 및 보정, DeepL 수동 파일 번역 기능을 합친 subtitle-extractor.py]
자막 번역만 도와주는 위 프로그램과 달리 Whisper의 자막 추출 기능도 포함합니다. 또한, 인공지능 음성 추출 시 생길 수 있는 자막 오류(반복되는 자막과 의미없는 짧은 자막)를 보정해 주는 기능을 추가하였습니다.
subtitle-extractor는 자막 추출 기능으로 static-ts와 Whisper중에 고를 수도 있습니다. 한글로 자세히 설명도 있으니 참고하시면 되겠습니다(수동으로 DeepL 파일 번역을 이용하고 나머지 전체 과정을 자동으로 처리하는 파이썬 프로그램).
https://github.com/sevengivings/subtitle-extractor
GitHub - sevengivings/subtitle-extractor: A Python program to automate the video AI speech recognition and translation process
A Python program to automate the video AI speech recognition and translation process - GitHub - sevengivings/subtitle-extractor: A Python program to automate the video AI speech recognition and tra...
github.com
아래는 stable-ts와 DeepL 앱을 이용하여 수동으로 파일 번역을 하는 모습을 담은 영상입니다. (참고: 최신 업데이트에서는 아래 영상처럼 선택하고 Enter키를 누르고 하는 작업을 최대한 생략할 수 있는 기능 - 번역된 docx를 자동 인식 - 도 추가했습니다. --framework stable-ts --auto_detect_docx 옵션을 이용하면 됩니다.)
[자막 추출 및 보정과 API 번역을 한번에 처리하는 subtitle-xtranslator.py]
이 프로그램은 subtitle-extractor.py에 API로 자막 내용을 번역하는 기능을 합해서 하나로 만들어 보았습니다. Google Cloud Translation, Naver Papago 번역 및 DeepL 및 DpL-Rapidapi를 통해 API번역하는 기능도 포함했습니다.
그 동안 만들었던 스크립트들을 집대성(?)한 셈입니다.
https://github.com/sevengivings/subtitle-xtranslator
GitHub - sevengivings/subtitle-xtranslator: A Python script to extract text from audio/video and translate subtitle
A Python script to extract text from audio/video and translate subtitle - GitHub - sevengivings/subtitle-xtranslator: A Python script to extract text from audio/video and translate subtitle
github.com
물론, 번역 API에 접근을 하기 위해 API key를 얻거나 구글 클라우드 번역의 경우 ADC(Application Default Credential)를 얻으려면 개발자 로그인을 해야 하는 번거로움이 따르지만, 각각 API들이 제공하는 무료 번역 용량을 활용하면 DeepL 앱/웹에서 파일 번역을 하지 않고도 번역된 자막(.srt)을 얻을 수 있다는 장점이 있습니다.
예를 들어, DpL-Rapidapi의 경우 월30만자까지 무료 번역이 되므로 개인 용도에는 꽤 괜찮다는 생각이 듭니다. DeepL은 월50만자까지 무료, 구글의 경우에도 월50만자까지는 무료입니다. 참고로, 파파고는 개발자에게 하루 1만자만 허용합니다.
아래는 stable-ts와 DeepL API 텍스트 번역을 이용하는 모습을 담은 영상입니다.
'AI' 카테고리의 다른 글
| DeepL번역으로 Youtube 유튜브 외국어 영상 자막 보기 (0) | 2023.09.16 |
|---|---|
| 자막 생성 Whisper 미디엄 모델을 2GB VRAM NVIDIA 노트북에서 이용하기 (0) | 2023.08.27 |
| DeepL 번역 API 써보기 - RAPID API 허브를 통하면 가능 (0) | 2023.07.13 |

